
堆基础
堆结构
PRE_INUSE和空间复用
当时学堆和做堆题的时候一直都没有注意到PREV_INUSE是怎么自然产生的(这么看来笔者有点学术不精了hhhh),但是会伪造PRE_INUSE和pre_size来达到向前合并堆重叠利用的目的
PREV_INUSE是chunk size上的一个标志位,主要是在free一个堆块的时候,检测它前一个(低地址)的堆块是否能和它合并
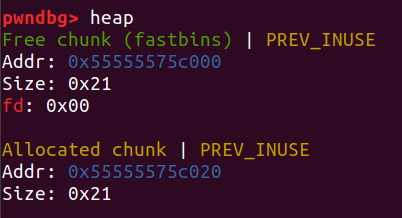
正常情况下fastbin和tcache不能合并,它们的PREV_INUSE位始终为1:
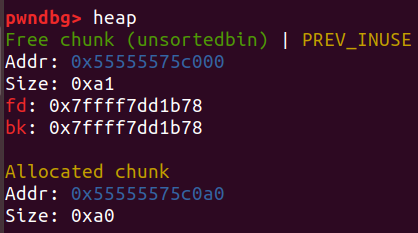
而unsorted bin就满足如果前面的堆块free,它的PREV_INUSE位就会被置为0:
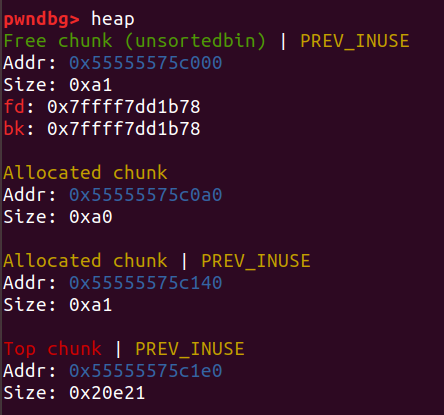
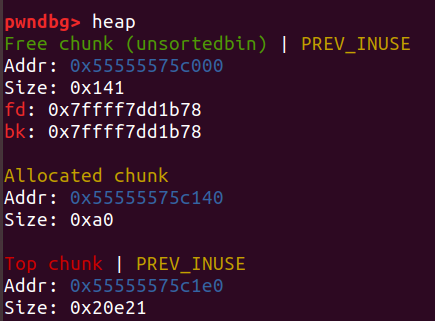
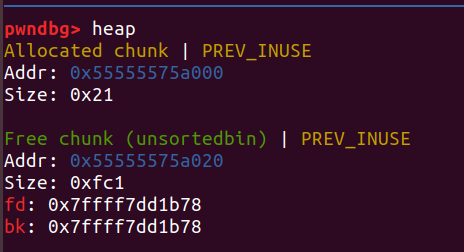
如果free一个堆块时,它前面已经有一个空闲的堆块,就会把这两个堆块合并成一个堆块:
谈谈空间复用
当malloc(0x?8)的时候,实际的除去presize和size的部分的大小是0x?0:
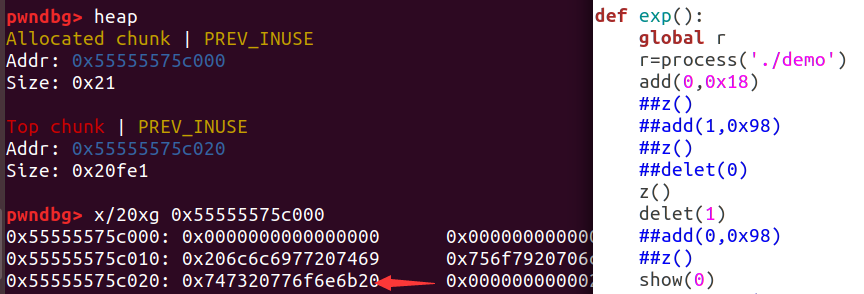
那么剩下的8字节往哪写呢?答案是箭头处——下一个chunk的pre_size位,这就是前一个chunk的content未16字节对齐的部分能够写到下一个堆块,也就是chunk的空间复用
Top_chunk
在程序运行的开端,内存会划分一个页对齐(0x10000整数倍+X)的堆块。当不能从bin中取出堆块时,用户申请的堆就是从这里切割的:
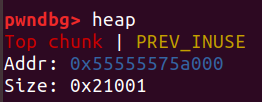
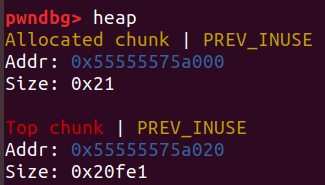
glibc源码注释里面对top_chunk的申明是这么说的:
1. The special chunk `top' doesn't bother using the
trailing size field since there is no next contiguous chunk
that would have to index off it. After initialization, `top'
is forced to always exist. If it would become less than
MINSIZE bytes long, it is replenished.我们重点放在最后一句上,如果top_chunk不断被切割,最后就有可能小于最小的chunk_size(64位下是0x20)就会被刷新
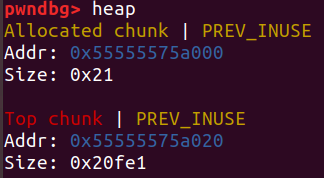
这里就涉及一个叫house of orange 的利用,利用思路就是修改top_chunk,然后申请一个比修改后的top_chunk略大的堆块,就能把top_chunk放入unsorted bin:

bin的容易疏漏的利用
Fastbin的合并——malloc_consolidate
一般情况下,两个相邻的free的fast chunk是不会合并的(即使修改了PREV_INSURE和pre_size也不会),但常见的有三种情况下会把单链表fastbin的堆块放到smallbin、unsortedbin这两个双向链表中通过malloc_consolidate函数完成合并
情况1:当申请了一个大于smallbin大小的堆块
部分源码:
else //if (!in_smallbin_range (nb)) 当申请的堆块大于0x3f0时(x64)
{
idx = largebin_index (nb);
if (have_fastchunks (av))
malloc_consolidate (av);
}首先申请一个0x20和0x60大小的堆块,free掉
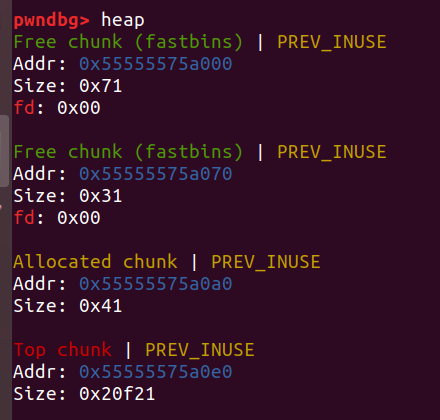
再申请一个0x400大小的堆块
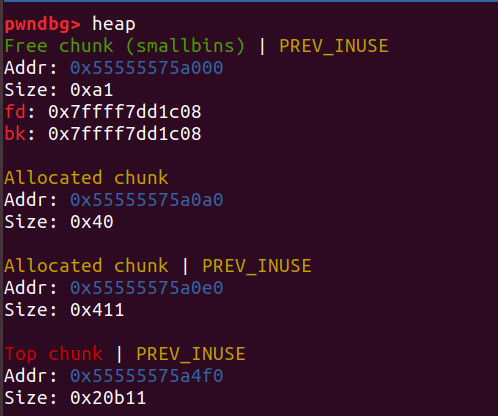
发现就合并并且放入smallbin了
情况2:当申请的堆块超过了TOP_chunk
先申请两个0x20的堆块和0x20f51大小的堆块,free掉前两个堆块
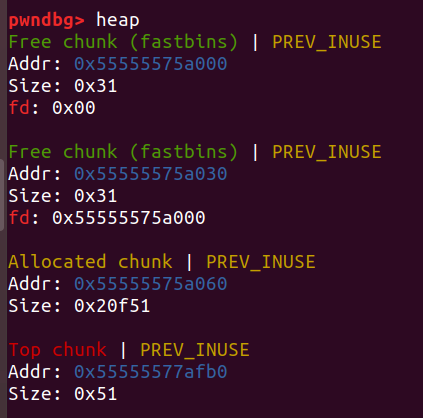
然后申请一个大于0x40大小的堆块:
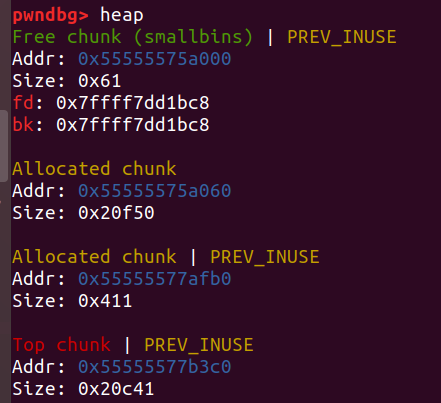
发现fastbin被合并了,而且topchunk被更新了
情况3:free一个大于fastbin大小的堆块
(ps:这个堆块必须紧贴着top_chunk)
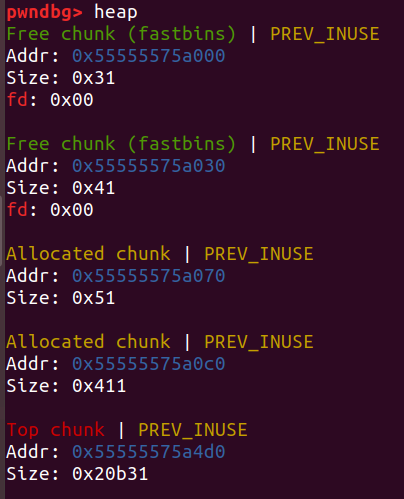
free掉大小为0x411的堆块
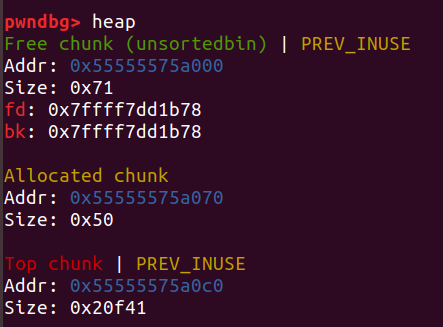
malloc_consolidate流程
一切的合并都离不开malloc_consolidate函数,它的具体流程就是,将可以合并的合并后或单个fastbin放入smallbin或unsortedbin,如果和topchunk相邻就和topchunk合并
unlink
触发条件
当malloc从双链表bin中取下一个堆块时或者free时发生堆合并时就会触发unlink操作
堆定位
前面提到过了fast bin chunk的合并和unsorted bin chunk的合并,单链表fastbin中chunk的合并是通过consolidate,那么unsorted bin和其它双链表呢?答案就是unlink
在介绍unlink之前,我们先介绍一下堆定位
我们都知道对一个双向链表中的节点,有前继和后继这两个概念。而bin中的节点chunk,同样有这样的概念,为了方便后面的讨论,我们定义一个chunk的前一个chunk为与它相邻的低地址chunk(记作b_chunk),而一个chunk的后一个chunk为与它相邻的高地址chunk(记作f_chunk)
用P(chunk)表示chunk的地址,那么我们可以得到如下堆定位的公式:
P(b_chunk)=P(chunk)-P(chunk)->pre_size
P(f_chunk)=P(chunk)+P(chunk)->size然而对双链表而言,是有指向前继后继的指针的,为什么不使用指针呢?个人理解是使用立即数,要比使用指针访问内存要快一些
向后合并
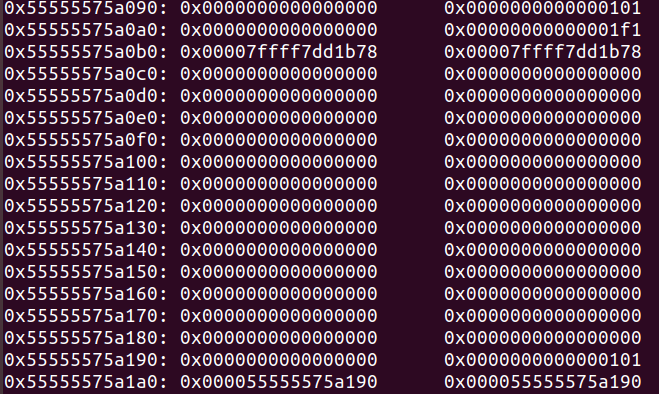
当free chunk p时,如果p的后面一个堆块是处于free状态(即后后个堆块的size的P位为0),那么就会将p和p的后一个堆块合并,并且合并表现的效果为p的size位的值变为p的size和后一个堆块size值的和
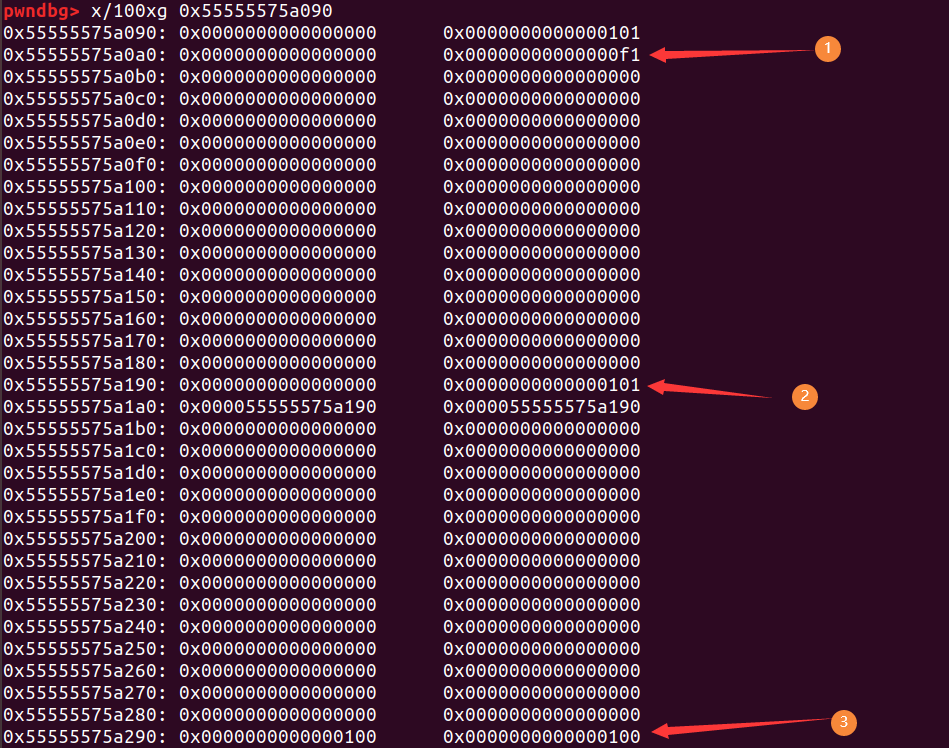
chunk1是我们伪造的堆块,此时free掉chunk1,由于chunk3的size p位为0,于是chunk1和chunk2就会合并,并且对chunk2执行unlink操作:
向前合并
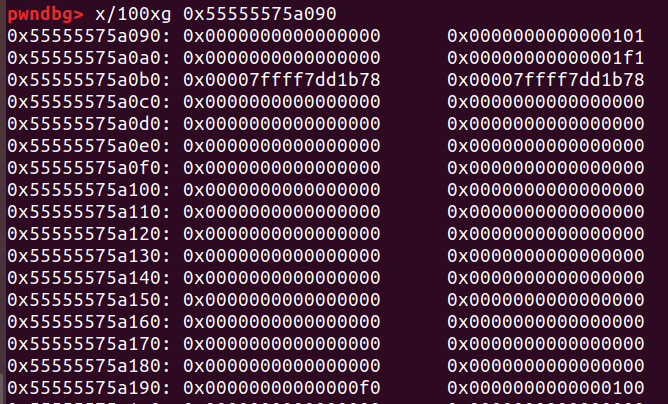
当free P时,如果P的前一个chunk处于free状态(即P的size P位为0并且pre_size位能定位到前一个堆块),那么P的前一个chunk就会触发unlink并和P合并

free掉chunk2,就会发现:
unlink的利用以及保护机制
unlink的过程其实和双链表的解链是一样的:
void unlink((size_t *)p,FD,BK)
{
FD->bk=BK;
BK->fd=FD;
}如果FD和BK是两个我们能够控制的指针,那么通过unlink我们就可以达到任意地址写的效果。比如FD=free_hook,BK=shellcode,在unlink过后free_hook的位置就被写上shellcode了
但是,在glibc 2.3版本过后,就增加了保护机制,主要是:
if(FD->bk != P || BK->fd != P) exit(-1)但是如果知道存放堆指针的地址和堆的首地址的话,还是能够绕过并且实现在存放堆地址的note位置写上一个我们自己的堆(可以伪造),这个利用在高版本一般只适用于NO PIE的情况
bin attack
fastbin attack
漏洞:
unsorted bin attack
largebin attack
tcache attack
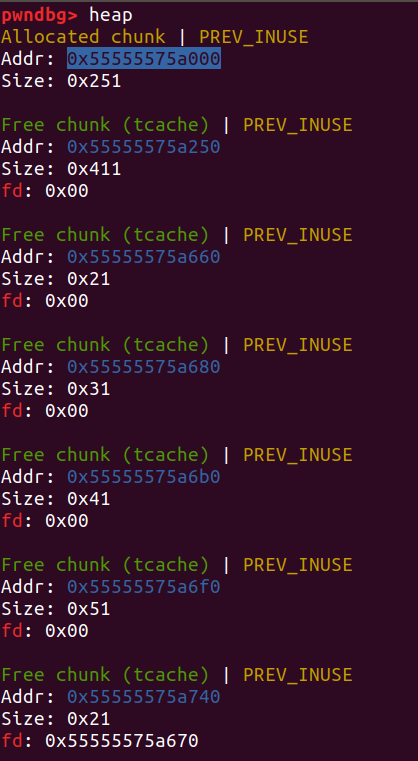
tcache bin是在glibc 2.26后加入的新的bin,较其它版本前的bin而言,在堆基地址的位置用一个初始化的大小为0x250的堆块取代了main_arena。这个堆块前0x10~0x50用0x40个字节存储0x20~0x410大小的堆块在tcache bin中的个数,后0x200个字节,每8位存一个对应大小的链表最后一个放入的堆指针
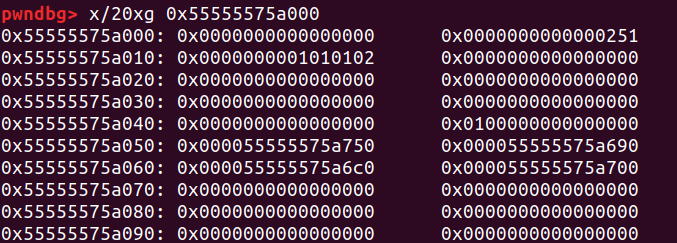
当malloc(P)时,首先会mov rbx,(P >> 1)-1,并且比较rbx和tcache_idx的大小,如果不大于则先考虑用tcache进行分配。接下来会找到heap+0x10+rbx*2的位置当作cnt,如果cnt不为空则取heap+0x10+rbx*8+0x80位置的指针出来分配。
了解了这个流程,我们就可以打tcache struct 然后改tcache head申请出我们想申请的东西如free_hook等